hallo herr zeuner,
die robots.txt steht üblicherweise im home des webaccounts im verzeichnis www. wenn mit subdomains gearbeitet wird, gibt es in jedem rootverzeichnis einer subdomain eine für diese subdomain spezifische robots.txt.
mehr info zum wesen der robots.txt und infos zum syntax finden sich da:
de.selfhtml.org/diverses/robots.htm
ein ausschnitt davon:
Es gibt Defacto-Standards im Internet, die einfach gewachsen sind, ohne es je zu einer RFC gebracht haben. Dazu gehört auch der Status, den die Datei robots.txt im Web hat. In einer Datei dieses Namens können Betreiber von Web-Projekten angeben, welcher Such-Robot welche Projektverzeichnisse auslesen darf und welcher was nicht lesen darf. Die Datei enthält also Anweisungen für Robots von Suchmaschinen. Die überwiegende Mehrheit der Robots moderner Suchmaschinen berücksichtigen das Vorhandensein einer robots.txt, lesen sie aus und befolgen die Anweisungen.
Zwar lässt sich auch in einzelnen HTML-Dateien mit Hilfe eines Meta-Tags für Suchprogramme das Auslesen erlauben bzw. verbieten. Doch das betrifft nur die jeweilige HTML-Datei und maximal alle weiteren, durch Verweise erreichbaren Dateien. In einer zentralen robots.txt können Sie dagegen unabhängig von der Datei- und Verweisstruktur Ihres Web-Projekts festlegen, welche Verzeichnisse und Verzeichnisbäume ausgelesen werden dürfen, und welche nicht.
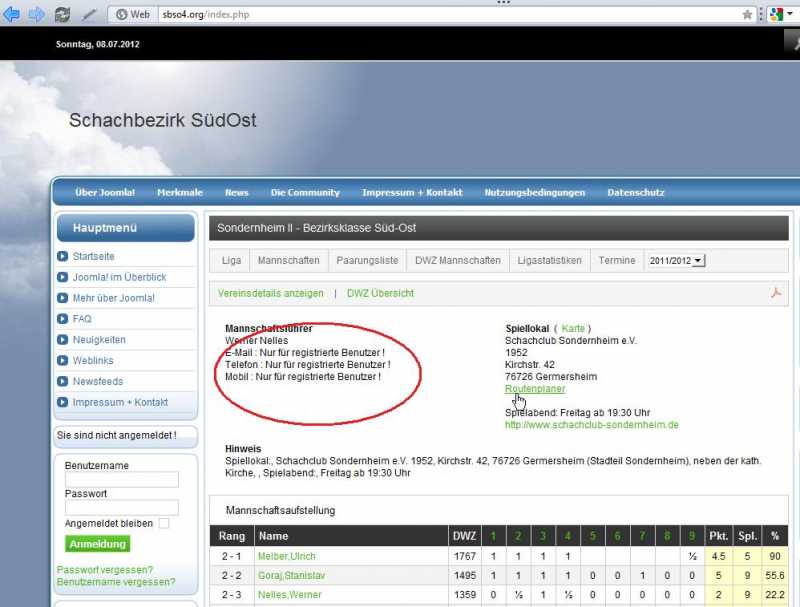
da die robots.txt damit zumeist oberhalb des clm-trees liegt, kann bei der clm-installation die robots.txt nicht modifiziert werden. hier ist der webmaster gefordert.
durch einträge in der robots.txt lässt sich da schön steuern, was die suchmaschine einsammeln darf und was nicht:
wenn sie wollen dass keine suchmaschine überhaupt auch nur das kleinste bisschen sammelt, so reicht der eintrag
User-agent: *
Disallow:/
in der robots.txt
meistens will man aber, dass die website auch von suchmaschinen gefunden wird. Aber man will eben nur bestimmtes zulassen.
hier ein beispiel für eine ergänzung in der robots.txt, wie ich sie auf webseiten mit CLM benutze
Disallow: /info/index.php?option=com_clm
Allow: /info/index.php?option=com_clm&view=verein
Disallow: /index.php?option=com_clm
Allow: /index.php?option=com_clm&view=verein
damit werden der suchmaschine generell alle zugriffe auf clm-daten in der DB verwehrt. und einzelne gewollte gezielt zugelassen.
erlaubt wird im obigen fall der zugriff auf die infoseite eines vereins, wo die adresse des spiellokals hinterlegt ist.
die ganze robots.txt könnte dann so aussehen:
User-agent: *
Disallow: /__my-akeeba-backup/
Disallow: /administrator/
Disallow: /cache/
Disallow: /components/
Disallow: /images/
Disallow: /includes/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /xmlrpc/
Disallow: /zufall/
Disallow: /info/index.php?option=com_clm
Allow: /info/index.php?option=com_clm&view=verein
Disallow: /index.php?option=com_clm
Allow: /index.php?option=com_clm&view=verein
wenn man das auf einer längere zeit "suchmaschinen-freundlichen" website jetzt neu reinbringt, vergisst die suchmaschine natürlich nicht schlagartig ihre daten. aber da die daten nicht mehr refreshed werden, werden sie nach gewisser auch aus der datenhaltung der suchmaschine entfernt.
HTH (hope that helps)
")